本文翻译自David Silver的《Tutorial: Deep Reinforcement Learning》,仅为个人笔记,如有写错,请联系susht3@foxmail.com,一起讨论。
本文结构分为以下几部分:
一. 前言
二. 深度学习简介
三. 强化学习简介
四. 基于value的强化学习
五. 基于policy的强化学习
六. 基于model的强化学习
一. 前言
深度学习 vs 强化学习
深度学习是特征学习,给定一个目标,学习目标的特征,使用最原始的特征输入,利用最少的领域知识。
强化学习是决策学习,针对具有选择action能力的agent,每个action都会影响到agent未来的状态state,利用一个标量的奖励reward来衡量成功度,目标是选择一系列的action以最大化未来的奖励reward。
深度强化学习结合DL+RL,RL定义目标,DL给出计算过程。
二. 深度学习简介
深度学习是用来实现机器学习的一种方法,深度神经网络用于理解深度表征。
1. 深度表征
深度表征由很多函数组成:

通过后向传播来更新梯度:

注意:网络过深会导致网络权重更新不稳定,会带来梯度爆炸或者梯度消失的问题,有时候需要进行梯度截断。梯度消失,层数越多,求导结果越小,所以越是靠前的网络层权重几乎不更新,只学习到接近最后输出层的几层网络。梯度爆炸,w比较大。还跟学习率有关。
梯度爆炸和梯度消失的本质原因:梯度反向传播中的连乘效应。
2. 深度神经网络
线性变换:

非线性激活函数:

loss函数:

有多种loss函数,平方差,对数似然函数,交叉熵等等。
3. 随机梯度下降法
对loss求导:

根据梯度下降的方向去调整w:

梯度下降法用于求解一个函数J(θ)的最大值或者最小值,而一个函数沿着梯度下降的方向是下降最快的,导数为0的那一点就是最值点。
现在目标是更新θ使得J(θ)最小,先选个初始值,然后不断往梯度的方向更新θ,直到θ的值不再改变。更新公式中学习率决定下降步伐,梯度决定下降方向。学习率用于控制迭代速度,取值太小会导致迭代过慢,取值太大可能错过最值点。
下山例子

这里纵坐标表示目函数的值(即 J( θ) 的值),两个横坐标分别表示参数 θ1 和 θ2。从初始点开总是往下降速度最快的地方走 ,这个地方也就是该点的梯度。
二维的等高线图

迭代特点:局部最优解
初始值有影响,初始值不同,得到的最小值也有不同;每一步都选择梯度下降的方向走,越是接近最小值,下降速度就越慢。
批量梯度下降:每次更新都遍历m个训练样本。缺点是训练集很大的时候,耗时太长。
随机梯度下降:依次使用第i个样本进行更新。缺点是它可能在全局最优解的附近徘徊,但是总体趋向全局最小值。
4. 权重共享
这是减少参数数量的关键!
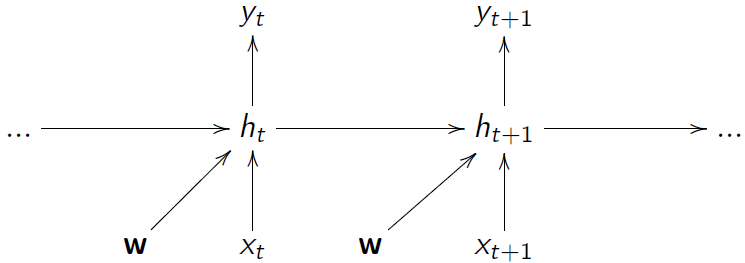
循环神经网络 RNN
在时间步长上共享参数
卷积神经网络 CNN
在空间区域中共享参数。

局部连接+权重共享。局部连接,每个隐藏层节点每次都只连接到一个局部区域。权重共享,卷积核的权重参数共享到所有的神经元。
三. 强化学习简介
1. RL的地位
无处不在的RL,作为许多领域的中心思想,优化决策以获得最佳结果。RL是一个序列决策问题,选择一系列的决策,使得最终收益最高。

(下面这段话引用自chenrudan)
强化学习是多学科多领域交叉的一个产物,它的本质就是解决“decision making”问题,即学会自动进行决策。在computer science领域体现为机器学习算法。在Engineering领域体现在决定the sequence of actions来得到最好的结果。在Neuroscience领域体现在理解人类大脑如何做出决策,主要的研究是reward system。在Psychology领域,研究动物如何做出决策,动物的行为是由什么导致的。在Economics领域体现在博弈论的研究。
2. 基本概念
Agent 和 Environment

在每个时刻下:
Agent:执行某个action at,然后接收来自环境的观察值ot与瞬时奖励rt
Environment:接收来自agent 的一个动作action,发出观察信号o(t+1),和奖励信号r(t+1)
(confuse:这里我觉得应该是ot和rt,也有可能是因为延时?)
State

Experience(历史状态):包含一系列的从第一个时刻开始的observations, actions, rewards
State(状态):
state是experience的总和。在某个时刻t下,状态state st是这个时刻以及之前所有时刻的所有历史状态的函数。其实严格意义上有两种state:environment state是环境自身的状态,agent state是环境反馈给agent的状态,也就是平常简称的state。环境会通过observation来告诉agent当前的环境状态。
观测性:在一个全观测的环境中,agent state等同于environment state。在某个时刻t下,state是当前时刻下观测值ot的一个函数,这里具备马尔科夫性质。在一个部分可观测的环境中,那么agent获取到的就不是最直接的environment state。
3. Agent的组成
一个Agent由policy,value function和model这三部分组成,但是这三部分不是必须要存在的。
Policy
policy是agent的决策行为,根据state来选择action,函数形式是将state映射为action,包含两种表达方式。确定性策略根据state直接选择某个action。随机性策略根据state生成action的概率分布,再从中选择action。

Value function
value函数预测当前state s下,未来可能获得的reward的期望,用来衡量当前state的好坏。Vπ(s)=Eπ[Rt+1+rRt+2+…|St=s],已有policy去选择action。而Q函数是奖励总值的期望,给定state s,action a,policy π,以及衰减因子γ,计算综合奖励的期望。Q用来衡量当前state下选择某个action的好坏。

注意!V和Q的区别在于,v是state value,Q是state-action value。Q里面的action a,不是用这个policy去算当前的action,而是当前state s已经采取了这个action a,后面的state s’再利用这个policy去选择后面的action a’,得到后面的reward。
如何更新value:

v可以采取某个policy选择一个action,或者遍历所有action选择v最大的。公式左边是即时奖励,右边是带有衰减因子的未来奖励。
贝尔曼方程
Q函数还可以分解为贝尔曼方程:

后面的r用Q(s’)来表示,s’为当前state s的下一个状态,a’为下一个action
Q函数是一个期望!关于后面state和action的一个期望。
优化价值函数
就是使得价值函数达到最大值。给定state s和action a,计算在所有policy下,当前state和action的Q函数,而最大的Q就是当前state和action下最优的Q函数。也就是说,在当前state下,每个action都有一个最优的Q函数。然后遍历所有action,在这些最优Q当中,再次选择一个最大Q,选择这个最大Q的action,以此作为当前state下的policy π。

注意:最优Q是带有星号的Q,Q其实就是在Q中挑选出最优的那个。
最优价值函数也可以分解为贝尔曼方程:

Q和Q的贝尔曼方程区别在于,Q是对s’和a’的期望,
Q是对s’的期望,因为Q*会选择使得Q(s’,a’)最大的action a’
Model
Model从经历中学习,学习环境的工作方式,预测下一个state或者下一次reward。

4. 实现强化学习的方法
前面提到agent的三个组成部分,可以根据这三部分去实现强化学习。
基于value的方法估算Q函数的最大值Q*(s, a),注意:这是基于任意policy下都能得到的最优Q值!policy π的参数会变,所以会有不同的π,那么不同的π就会得到不同的action,其实 Under any policy 最后就是会遍历到所有的action。
基于policy的方法寻找最优policy π*,在这个policy下能够得到最大的未来奖励。
基于model的方法对环境进行建模,用这个模型来进行规划,比如前向搜索。
DeepMind-DRL例子
游戏:Atari 游戏、扑克、围棋
探索世界:3D 世界、迷宫
控制物理系统:操作、步行、游泳
与用户互动:推荐、优化、个性化
实现方法:使用深度学习去模拟Q,policy,model,再用随机梯度下降法去优化loss函数。
四. 基于value的深度学习
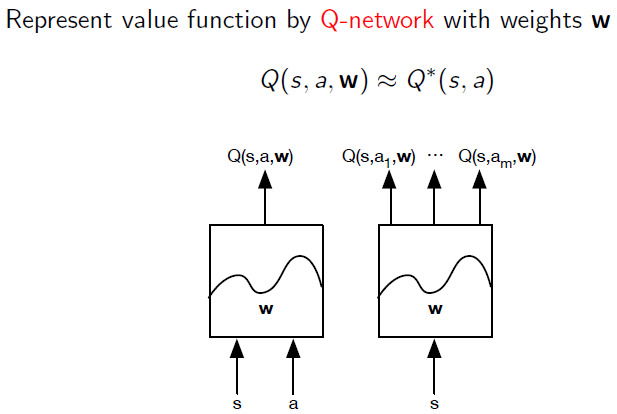
1. Q网络
用神经网络对Q进行建模:
第一类做法: 输入s与a,输出一个Q(s,a,w)值,其中w为网络权重
第二类做法: 输入s,输出一个Q(s,ai,w)的向量,维度为action的维度大小
2. Q-Learning算法
目标函数
把最优的Q*定义为我们要求的目标,用随机梯度下降法去最小化均方差MSE

神经网络所产生的问题
采样之间的相关性:当前的state和action和上一步执行的action非常接近!数据集具备序列性质,具有很强的相关性。
目标的不稳定性:注意 我们学习的目标是依赖于目标本身的。不平稳性会导致近似函数螺旋式失控,policy会有震荡。
为了解决这些问题,接下来会介绍DQN算法。
3. DQN算法
经验回放
从过往的经历构建出一个数据集(s,a,r’,s’),从这个数据集中随机采样一些经历(s,a,r,s’)进行更新。

这些采样出来的经历是独立分布的,这样就可以打破训练集之间的相关性。
注意!构建数据集的时候使用(s,a,r’,s’),但是采样的时候使用(s,a,r,s’)。为啥?还是因为 延迟性??mark
固定target-Q网络
公式左边是target Q,右边是我们训练的Q网络。使用MSE损失函数。

这里暂时hold住Q网络以前的权重w-,用这个固定住的参数w-去算target Q,然后周期性更新W-为w。而Q网络仍是你Q网络,Q网络是时刻更新的,只是target Q会暂时固定住的。这样可以减少震荡。
剪切回报/值范围
设置reward在[-1,+1]范围内,可以保证Q的值不会太大,好求梯度。
DQN玩Atari游戏
从像素s中端到端学习Q(s,a),输入是前面4帧的像素,作为state,输出是对应按钮位置的Q(s,a),那么reward就是执行这个action后,得分和从前的差值了。

接下来会介绍一些基于DQN的改进方法。
4. Double-DQN
用两个网络,Q(w-)用于选择action,Q(w)用于评估action

Double-DQN与DQN的区别在于,在下一个state s’中,DQN遍历a’使用max Q作为target,这里评估action的Q是暂时固定住的Q,这是会有偏差的。Double-DQN同样也是先选出max Q对应的action a’,然后再用网络Q(w-)去评估这个action,以Q(a’,w-)的结果作为target Q。
5.确定优先级的经验回放
从前做经验回放的时候,所有经历都是等权重的。这里以DQN的误差去衡量经历的优先级,越是做得差的经历越是要回放。

6. 决斗网络
将Q网络分成两个channel,Action-indepent用于计算当忽略了某些动作时 你会得到多少奖励。在V(s,v)中,小v是V网络的参数,s是state。Action-dependent用于计算当你采取了某个动作a时 你会得到多少好处。最后结合这两部分,总和作为Q。

加速训练
Gorila结构,使用不同机器,并行化运行Q网络。
如果你没有google的资源,还可以使用异步强化学习:利用标准 CPU 的多线程;并行执行agent的多个实例;线程间共享网络参数;并行消除数据相关性;替代经历回放;在单个机器上模仿Gorila的加速过程。
五. 基于policy的强化学习
1. Deep Policy Networks
策略方式
随机性policy:根据state生成action的概率分布,表示在某个state下执行某个action的概率。随机性policy比确定性policy要好。
确定性policy:根据state直接生成action

目标函数
将目标函数定义为 总reward,使用随机梯度下降法来最大化目标函数。

这个写法感觉有点怪怪的,其中u是网络的参数,π是policy,点号不知道是什么。可以写成,在这个policy下,所有action对应的的总reward的期望。目标形式依然是优化Q,但是和前面不同的是,这里Q的参数是policy的参数。
Policy Gradients
目标函数分别对随机性policy和确定性policy求梯度:

对于随机性policy,把L(u)写成E的形式再求导,就可以得到图中结果。公式中第一项是score function,用来衡量policy选择这个action的程度,第二项是Q,用来衡量这个action的好坏。如果这个action表现较好,我们就调整policy趋近这个action,最终拉近这两个分布。
对于确定性policy,链式求导。
2. Actor-Critic算法
Actor-Critic算法包含两个网络,Actor 网络用于选择action,Critic 网络用于评估这个action的好坏程度,计算value function,去指导Actor网络更新梯度。Actor基于policy gradients,可以在连续的actio空间选择一个action,而critic基于Q-learning,可以进行单步更新,注意policy gradient是回合更新,会降低学习效率。所以Actor-Critic是结合了基于policy和基于value的方法。
Actor 网络
Actor网络用于学习policy,输入state,输出action
Critic 网络
Critic网络用于学习Q,以评估action的好坏,输入state和action,输出对应的Q,Critic的目标就是估计这个policy的贝尔曼方程。
那么接下来actor就可以用这个Q去更新自己的梯度,往提高Q的方向去更新。

这里w是critic的参数,u是actor的参数,这里是对u求导,以更新policy。
3. Asynchronous Advantage Actor-Critic (A3C)
V是state-value function,用于评估在当前state的好坏。
Q则是state-action value,这里和之前定义的Q所有不同,这里只有前n个reward是用reward来算,后面的reward总值使用V去评估。

Actor 网络
与先前actor不同的地方是,公式右边变成Q-V,这个就叫Advantage,表示采取这个action比平均state下要好出多少。
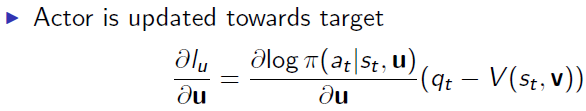
Critic 网络
Critic网络评估的是V值,目标函数是 根据q 和V 的MSE函数。

咩咩咩???mark
A3C用于Labyrinth游戏
定义state为当前画面的像素,使用lstm对state进行建模,每个state输出action的概率分布,以及这个state的value值。

DRL如何处理高维连续action空间?
如果对Q算一个max,计算量会非常大。
Actor-Critic算法不需要算max Q,避开了这个问题。
Q值是可微的。
确定性的policy gradient会对Q求导。
4. Deep DPG
DDPG同时借鉴了DQN和Actor-Critic,DDPG的优势在于连续action空间。
经验回放
前面提到的。
Critic 网络
DDPG和DQN不一样的地方在于,DDPG多了个policy π,π的参数为u-,target-Q中会暂时hold住u-和w-

Actor 网络
Actor网络更新的时候也是朝着提高Q的方向。
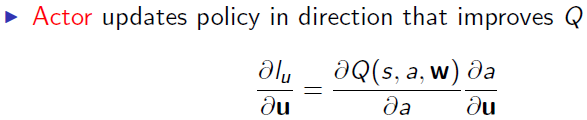
DDPG用于Simulated Physics

六. 基于model的强化学习
未完待续 暂时写不下去了….回宿舍
