这段时间笔者在学习CS234强化学习课程,此文为Lecture1-4的总结博文。
本文结构:
MDP Planning
Basic RL with Lookup Tables
Generalization in Model-free RL
一. MDP Planning
在讲MDP Planing前先介绍一下MDP,马尔可夫决策过程。
Markov Decision Process
马尔科夫决策过程,MDP可以表示成五元组:
S表示一个有限的state集合,A表示一个有限的action集合,P是状态转移矩阵,在state s下执行action a 然后转移到状态s’的概率,γ是衰减因子,用来计算在state s后的未来总reward之和,也就是return。
MDP会有一个policy π,这里的Policy是指,在state s 下,执行的action的概率分布,这个叫随机性policy,比如在state s 下,现在有两个action,action a1和action a2,那么假设执行action a1的概率是0.8,那么执行action a2的概率就是0.2,我们可能会执行action a1,也可能会执行action a2。
但是在确定性的policy中,它会告诉你执行action a1或者执行action a2。
MDP还有两个价值函数,用来衡量当前的状况。Vπ(s)用来衡量state s的好坏程度,它是从当前state s开始,后面使用policy π去选择一系列action,得到的return的期望。
Qπ用来衡量在state s下执行action a的好坏程度,它是在当前state s下选择了action a,然后后面再去用policy π去选择后面的action,得到return的期望。
MDP Planning
MDP planning就是在已知MDP的情况下,去做planning。MDP planning跟强化学习都是序列决策问题,不同的地方在于,强化学习不知道外界的环境是怎么样的,MDP已经知道了环境是怎么样的。
举个打游戏的例子,强化学习就相当于,不告诉你游戏规则就直接让你玩,你只知道你可以执行哪些action,但是你不知道执行什么样的行为是好的,什么样的行为是不好的,你也不知道执行了某个action会跳到一个什么样的state,所以你会不断去尝试去猜测这个游戏应该怎么玩。MDP planning就相当于在游戏当中开挂了,知道了自己执行某个action后的状态会是什么样,再去优化自己的policy。这两者之间是有联系的,强化学习既要学习这个游戏的规则,又要学习怎么做planning。
在已知MDP的情况下,MDP planning要解决的问题有两种,第一种是prediction问题,给定一个policy,去评估一下这个policy怎么样,目标是算出在这个policy下,每个state的value function。第二种是control问题,这里也给出一个policy,但是它要去优化这个Policy,所以它的目标不仅是计算出最优的value function而且要给出最优的Policy。
在MDP Planning中,用Iterative Policy Evaluation可以解决prediction问题,用Policy Iteration和Value Iteration可以解决controll问题。
Bellman Equation
贝尔曼方程,可以把一个问题划分成子问题求解,value function跟q function都可以表示成贝尔曼方程的形式,这里不再做贝尔曼方程的推导,只回顾贝尔曼方程的形式。
贝尔曼方程分成两种,一种是期望方程,一种是最优方程。在贝尔曼期望方程当中,Vπ(s)是在state s下,基于policy π的价值函数,假设从s可以转移到s’,那么V(s) 就是关于V(s’)的期望。V用来衡量当前state的好坏,Q用来衡量在当前state的情况下,选择某个action的好坏程度。
对应的,在贝尔曼最优方程当中,V*(s)是在state s下,遍历所有的action,选择最大的value作为最优的value,其实V*(s)也是关于V*(s’)的期望。根据V*可以求出Q*,选择Q*对应的的action作为π*。
Iterative Policy Evaluation
把v用贝尔曼方程的形式表示出来后,我们就可以迭代去计算V函数。
迭代策略评估,要解决的问题是,评估一个policy,也就是基于当前的Policy,计算出每个状态的value function,目标是在已知policy下得到收敛的value function。迭代策略评估使用贝尔曼期望方程去更新value值,假设state s能到达state s’,那么第k+1次迭代中衡量state s的V,用第k次迭代中s’的V去更新。
举一个网格的例子,左上角和右下角是目的地,每走一步reward-1,这里面设置policy是random policy,我们现在要计算每个网格state对应的value

K=0,初始化所有的state的取值v(s)为0
K=1,根据贝尔曼方程,上一次迭代的v(s‘)都是0,这一次算出来的v(s)都是-1
K=2,-1.7 = -1 + E(0,-1,-1),理论上s’是属于整个集合s的,但是在这个例子里面-1.7的下一个状态s’实际上是只有三种可能的,所以在-1.7对应 的状态转移矩阵中,这三个状态s’的转移概率都是1/3,然后其它s’的转移概率都是0。
-1.7右边,-1.7下面的两个-2.0,右-2.0 = -1 + E(-1, -1, -1),下-2.0 = -1 + E(-1, -1, -1, -1),虽然算出来都是-2.0,都是他们对应的状态转移矩阵是不一样,右边的-2.0可以转移到3个状态,下面的-2.0可以转移到4个状态。
k=无穷处,已经迭代到收敛,收敛之后这些value值都不变了,比如-18 = -1 + E(-14, -14, -20, -20) = -18。
Policy Iteration
策略迭代解决的是control的问题,是在前面策略评估的基础上更新策略。策略迭代分为策略评估和策略提升两部分。
策略评估,基于当前的Policy计算出每个state的value function:
策略提升,基于刚刚算出来的v,对每个action再算一个Q ,选择使得Q最大的action,作为当前最优的Policy,也是下一步计算V的policy。
一开始给定一个policy,V也初始化为0,然后更新policy,用这个更新后的policy去重新评估v,再不断更新,最后会收敛要最优的V和policy。
还是举网格这个例子,我们刚刚是给定policy求解v值,现在要求最优的policy。需要注意的是,图中这个例子,在评估策略的时候依然使用固定的policy,这不是真正的策略迭代方法,真正的策略迭代在策略评估这一步需要用当前的policy。

这里左边计算v值的时候,使用的policy应该改成当前的policy,而不是random policy
右边根据v值计算每个action对应的Q值,然后更新policy
现在考虑红圈圈住的那个state,第0次迭代的时候是random policy,第1次迭代的时候,根据左边的v去计算4个action所对应的Q值,这4个Q值是一样的,所以policy有4个箭头,第2次迭代的时候,算出来左边和上面的Q值是最大的并且是一样大的,所以policy有两个箭头。

一直迭代直到policy收敛,最终会得到最优的policy。在这个例子中,在k=3的时候poliy就已经收敛了,但是v还没有收敛,迭代到最后v和policy会一起收敛。如果更新策略评估中的policy,那么v和policy应该是连接收敛的。
Value Iteration
策略迭代解决的是control的问题,其实值迭代解决的也是control的问题,虽然在迭代的过程中没有显式计算出policy,但是在得到最优的value值之后也就能得到最优的policy,这里选择使得v最大的action作为Policy。这里用的是贝尔曼最优方程,是不对应任何policy的。前面策略迭代用的是贝尔曼期望方程,对对应于某个policy的。
值迭代的最优化原理是当且仅当任何从s能达到的s′能在当前policy下获取最优的value,那么s也能在当前policy下获得最优value
从这个原理出发,如果已知vs′的最优值,那么就能通过贝尔曼方程将v(s)的最优值推出来。因此从终点开始向起点推就能把全部状态最优值推出来。
现在对比一下这两种方法,走迷宫,我们要从起点走到终点,每走一步reward是-1。

在值迭代的方法中,每一个格子里面的数字表示这个state对应的value,我们要做的是求出这些value,再根据value去选择action,比如在-15这个位置,有3个action,一个是向上走,一个是向下走,现在求出来上面的Value值是-1+(-14)=-15,下面的value值是-17,那么我们就会选择往上走。这本身也是一种policy。
在策略迭代的方法中,直接算policy,每个格子里面的箭头是表示当前应该往哪个方向走。
二. Basic RL with Lookup Tables
强化学习分为model based跟model free两种,强化学习是不知道环境的,上一节讲的mdp planning也是已经给出了状态转移矩阵和rewrad函数。Model based则是需要自己学习环境的状态转移矩阵跟reward,然后再去做planning。相当于environment + mdp planning。Model Free是指不需要去猜测环境的state和reward,直接跟环境去做交互,直接从环境中获取state和reward,我们这里只讨论model-free的方法。
前面的mdp planning通过动态规划的方式去解决已知环境的MDP问题,然后又根据是否更新policy将问题又划分成了prediction和control问题。
那么在未知环境下,也就是model free的情况下,同样需要解决prediction和control问题,这种新的问题只能与跟环境进行交互,得到一些经历去获取信息。
解决prediction的问题,是通过估算未知MDP的value function,解决control的问题,是最优化未知MDP的value function以及policy,所以上面这种又叫做value-based,下面这种叫policy-based
这一节讨论的是在未知环境中解决predict的问题,通过蒙特卡洛方法和时序差分学习,去评估policy。
Monte-Carlo Policy Evaluation
蒙特卡洛策略评估,目标是基于某个Policy,从过往的经历中,去学习value函数。这里必须是完整的episodes,一个完整的episode指的是,从某个初始状态开始,一直执行到终止状态,这样一次遍历。
在讲MDP的时候讲到,每个state的value值是return的期望:
蒙特卡洛策略迭代方法,用多条经历的平均return,去代替return的期望。蒙特卡洛策略迭代又分成两种,First-Vist MC和Every-Vist MC。

这个图里面,给出了三条经历,每一条经历从state s0开始,执行一个action,会得到一个reward,reward就是蓝色的小点,然后会跳到下一个state,一直执行到终止状态。这里设置无衰减,R1(s)=1-2+0+1-3+5=2,R2(s)=-2+0+1-3+5=1。
假设我们现在要求状态s的value值,在第一条经历中,经过了两次s状态,在第三条经历中也经过了两次s状态。如果用first visit的方法,每一条经历只采第一个状态s,用这两个s去算return的均值。如果是every visit的方法,每一条经历的所有s状态,都要访问,就是说对这四个s算return的均值。
这些方法,有个问题就是,必须等到执行完所有episode,才能算value。假设有新来了一条经历,又要重新算。
Incremental Monte-Carlo
针对这个问题,提出增量式的蒙特卡洛计算方法,当新来一个经历的时候,直接更新v,不用重新算。
这个公式我们之前推导过,其实和前面求均值是一样的,只是换了种写法。
为了计算更平稳,这里用α代替1/N:
我们现在解决了新经历这个问题,现在面临的另一个问题就是必须要走完一条经历的所有流程,得到return,才能计算value
Temporal-Difference Learning
时序差分学习解决了这个问题。
蒙特卡洛方法用真实的Gt值去更新value,既然我们现在不想走完整个流程再算value,那就预算return,时序差分学习用估算的return值去更新value。
TD(0)是指在某个state s下执行某个action后转移到下一个状态s′时,用去估算真实s的return, 再更新vs。
其中就叫做TD Target,
叫做TD Error
这是最简单的算法,我们也可以,先执行n个action转移到状态s’,再估算s的return,这个就叫Gt(n)
下面举个例子,来说明一下蒙特卡洛跟时序差分的区别。这个例子的policy是一直往左走。

现在我们考虑这么一个经历trajectory = (S3,TL,0,S2,TL,0,S2,TL,0,S1,TL,1,S1)
第一个问题:first visit MC算出来所有状态的value是多少?我们知道value就是return的均值,现在γ=1,那么所有时刻访问过的state的return都是1,所以对应的value也是1,所有state对应的value就是[1 1 1 0 0 0 0]
第二个问题:every vistit MC算出来的v(s2)是多少?也是1因为所有时刻访问的state的return都是1,return的均值也是1,所以s2对应的value是1
第三个问题:TD对state的评估结果是多少?我们先把这一条经历拆成四个元祖,TD是用Rt+1去更新Vst,只有第4个元祖的reward是1,也就是只有s1估算的return是1,那么s1的value值是α, 其它state的value值是0,所以所有state对应的value就是[α 0 0 0 0 0 0]
第四个问题:前面是只更新了一次,假设更新很多次,那TD和MC又怎么更新?TD会不断从过去的元祖里面重复采样更新,MC不断从过去的经历中重复采样更新。
在这个例子,我们只有一条经历,现在对这条经历重复采样,分别求MC跟TD的结果。
首先,蒙特卡洛的结果不变,因为MC对某个state求value的时候,是对这个state的return求均值,重复采样,相当于对多条相同的经历,求return的均值,均值是不变的,所以在first-visit中所有state对应的value依然是[1 1 1 0 0 0 0]
在TD中,在这条经历的基础上,假设又采样出这些下面这些元祖,现在求TD的结果。最初在这个经历后,我们算出来s1的value值是a,其它state是0。然后用下面第一个元祖更新,reward是0,所以value都不变,第二个元祖,r=1,更新v(s1)=2a, 3a, 4a,则最后所有state对应的value就是[4α 0 0 0 0 0 0]
最后一个问题,在TD中,这些元祖采样的顺序,会不会影响到算法的收敛?
这个肯定会影响的,因为我们是根据v(st+1)更新v(St),采样顺序不同,v(st+1)就会不一样。那么,什么样的采样顺序才是一个好的顺序呢?应该先采那些临近后面state的样本。
MC方法会收敛到最小化均方误差的解,而TD方法会收敛到MDP问题的解,会找出状态转移概率和reward函数,还是在解决MDP问题。
Policy Evaluation
下面总结一下用Policy Evaluation解决强化学习问题的一些算法。

最左边的竖线表示有没有考虑所有的可能发生的情况,如果考虑了所有的可能发生的情况那么就是动态规划,如果是部分采样就是时序差分。
下面的横线表示如果在一次经历中,考虑了全部的动作就是Monte-Carlo,如果只考虑部分动作就是时序差分。
如果又考虑全部情况又考虑每一种情况的全部动作就是穷举。
1)Dynamic Programming Backup:这个图表示动态规划考虑了所有可能发生的情况。白色的点表示state,黑色的点表示action,在state st下,有两个action可以选择,选择某一个action之后,会得到一个reward rt+1,到达状态st+1,绿色的T表示这一条经历结束了。求解v(st)需要回溯到所有的st+1.
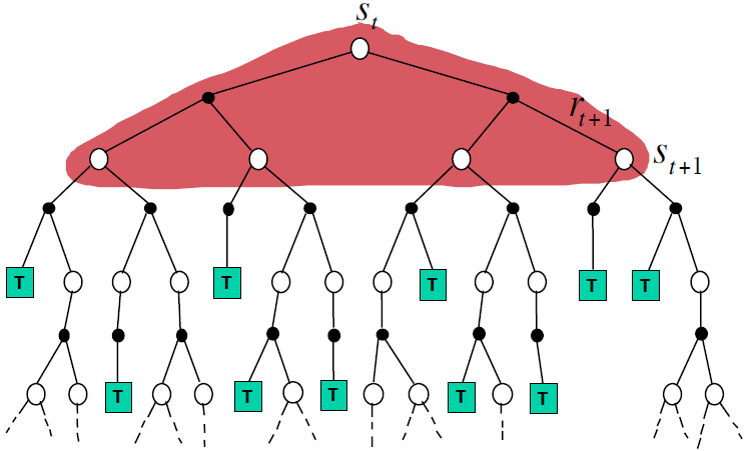
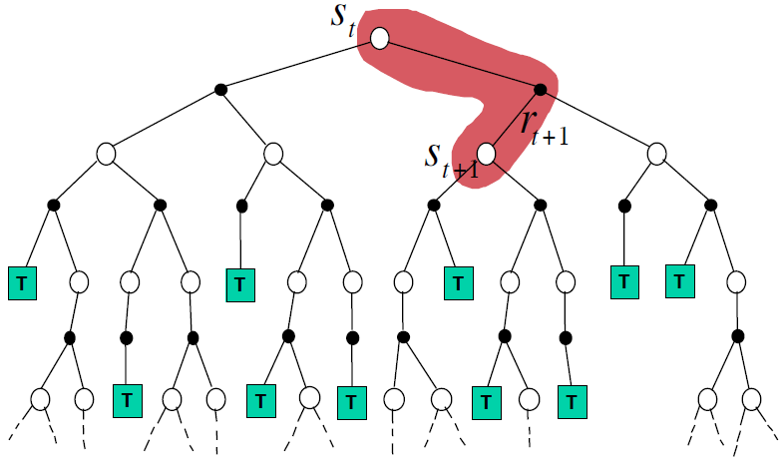
2)时序差分,求解v(st)需要回溯到,在t时刻选择某个action后到达的st+1
3)蒙特卡洛,求解v(st)需要回溯到一整条路径。

三. Generalization in Model-free RL
在现实生活中,状态一般是很多的,比如说大型画面游戏,每一帧就是一个state,或者是那种不连续的状态,比如状态是0.1, 0.01这种。

针对这种大规模的状态,如果算出每种状态下的真实value function,没有足够的内存也没有足够的计算能力,此外考虑到比较接近的状态它们的值函数取值应该是很相似的,这是一种泛化能力。
所以需要一个算法去近似价值函数,可以用线性特征组合,神经网络等等。这里我们只讨论线性的方法去逼近价值函数。
Linear Value Function Approximation (VFA)
线性特征组合,把state表示成特征向量,对这些特征向量进行线性组合,算出来这个值就是这个state所对应的value。
定义目标函数是真实v值和算出来v值的平方差,在所有policy下的期望:
用梯度下降法去更新参数:
如果把价值函数近似用在蒙特卡洛方法上,目标就是去近似Gt,这里面Gt是对真实V值无偏差的估计,所以这属于有监督学习,监督信息就是Gt。蒙特卡洛方法会收敛到局部最优解
在时序差分中,目标是近似TD target,这个return是对真实v值有偏差的采样,就是说它实际上并不等于真实v值,只是一个估算值。同样是有监督学习。TD会收敛到全局最优。
